2024. 5. 22. 18:03ㆍDB
실시간 애플리케이션을 위한 실시간 성능.
※ 2024년 4월 16일 AWS Database Introductory Training - Amazon ElastiCache 교육의 내용을 정리한 포스팅입니다.
1. Amazon ElastiCache
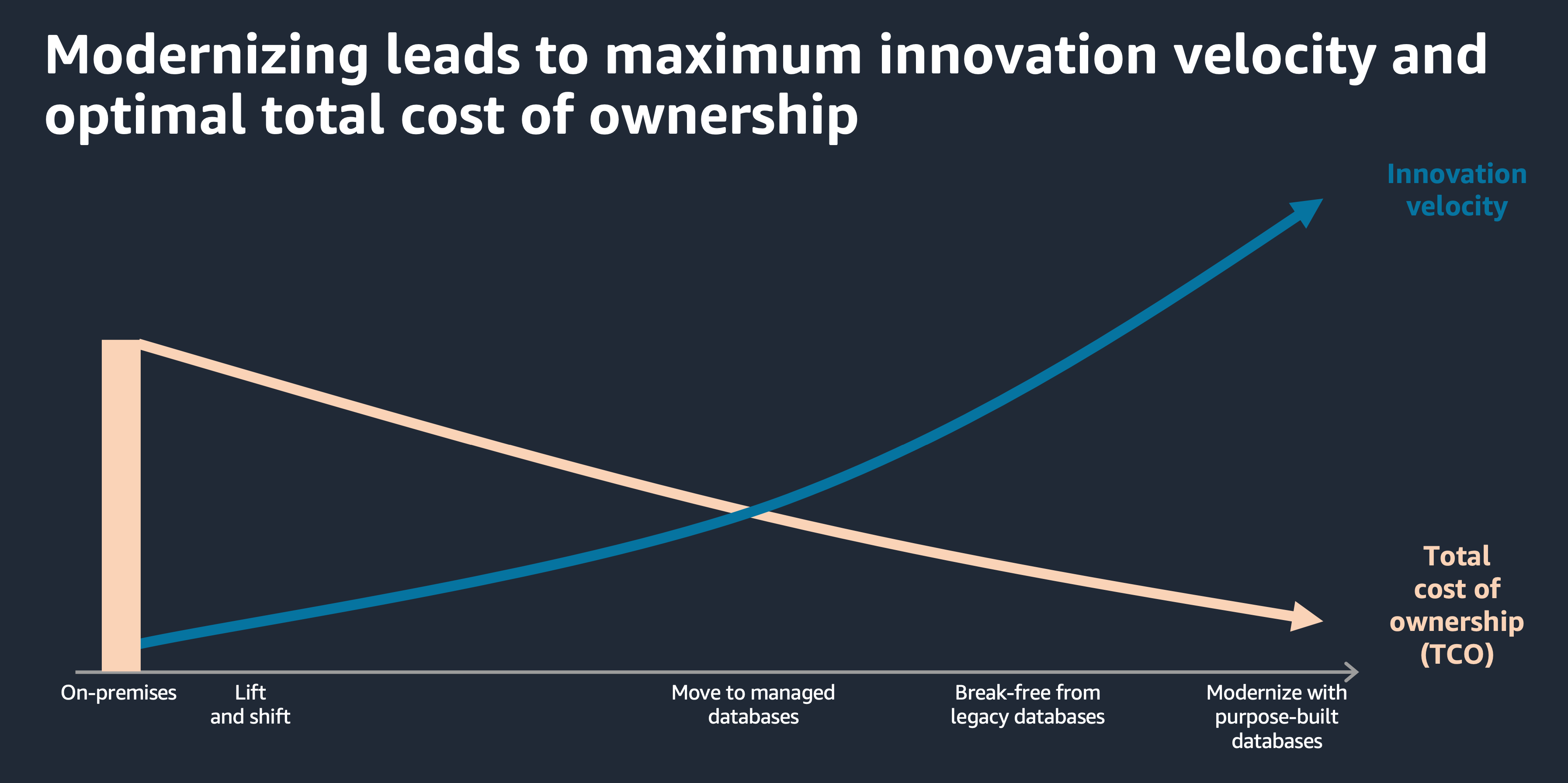
현대화가 진행될 수록 총 비용(TCO, total cost of ownership)을 절감할 수 있고,
이에 의해 시간도 절감할 수 있습니다.
실시간 서비스를 위해서는 microseconds로 데이터에 접근할 수 있어야 합니다.
microseconds로 데이터에 접근하기 위해서는 캐시를 활용해야 합니다.
다음과 같은 경우에는 캐시를 사용하는 것을 고려해보는것이 좋습니다.
- 동일한 쿼리가 빈번히 발생되는 경우
- 읽기 지연시간이 높은 경우
- 높은 I/O 나 과도한 읽기로 인한 비용을 절감하고 싶은 경우
캐시를 쓰게 되면 다음과 같은 주요 이점들이 있습니다.
- 규모에 따른 예측가능한 비용을 보장하여, 총 비용을 절감할 수 있다
- 별도의 I/O 수수료가 없습니다 (인스턴스당 수수료만 지불하면 됩니다.)
- DB 부하를 줄여 애플리케이션 응답 시간을 향상시킵니다
- 읽기 처리량을 확장시킬 수 있습니다.
이러한 이점들을 고려하여, FE가 BE에 접근하지 않고 캐시를 이용하게 되면 BE 부담도 줄이면서 빠르게 데이터 접근이 가능하게 됩니다.
redis나 memcached를 직접 설치하는 경우, 유지보수나 scale out에 어려움이 크고 장애 대응이 까다로운 반면 ElastiCache를 사용하게 되면 아래와 같은 측면에서 장점이 큽니다.
- 성능 및 확장성
- 고가용성 및 엔터프라이즈 보안
- 총비용 감소
- Fully-managed
- 레디스 Api를 완전 지원하기 때문에 유연하게 접근이 가능합니다.
- 오픈소스 호환을 지원
- EKS, lambda 등과 연동하여 사용 가능
또, 오랫동안 접속하지 않은 데이터들은 하드에 저장하여 비용을 절감시켜주는 data tiering 기능도 제공하고 있습니다.
ElastiCache는 적용할 수 있는 사용 예시로는 아래와 같은 서비스들이 있습니다.
- microseconds로 데이터에 접근되어야하는 서비스
- 실시간 데이터 분석 서비스
- 실시간으로 지리적 정보를 계산하여 거리감 등을 계산하는 Geospatial
- 미디어 스트리밍
- 실시간 랭킹 조회
Amazon ElastiCache Serverless
기존 ElastiCache와의 차이점은
설정을 해두고, 요청이 오면 요청 오는만큼 처리되는 것으로, 인프라 관리 없이 매우 빠르게 고가용성 캐시 생성이 가능하여 애플리케이션 액세스 패턴에 따라 즉각적인 확장이 가능합니다.
매우 빠르게 생성할 수 있으나, 기본 엘라스틱캐시보다 비용이 조금 더 비쌉니다.
요청하는 만큼 비용이 듭니다.
2. Amazon MemoryDB for Redis
Amazon Memory DB for Redis는 아래와 같은 주요 특징을 가지고 있습니다.
- 성능 및 확장성
- 뛰어난 내구성(durability) 및 고가용성
- 엔터프라이즈 보안
- Fully-managed
- 오픈소스 호환을 지원
ElastiCache와 특징이 거의 유사하지만, 내구성에 대한 차이점이 있습니다.
Amazone MemoryDB for Redis는 트랜잭션 로그에 커밋해두기 때문에 다운되어도 복구가 가능합니다.(데이터가 휘발되지 않습니다)
때문에, 내구성이 필요하지 않고 일시적으로 저장되는 데이터는 ElastiCache를 활용해야하고, 빠른 access 속도가 필요하지만 내구성도 필요하다면 Amazon MemoryDB for Redis를 사용하는 것이 좋습니다.
AWS에서 제공하고 있는 In-Memory DB들은 아래와 같은 차이점을 가지고 있습니다.

Elastic for Memcached는 failover 지원도 안하고, 데이터타입도 string만 지원하지만, 멀티스레드를 지원합니다.
다만, 멀티스레드도 결국 cpu자원을 이용하는 것이기 때문에 때에 따라 더 느려질 수 있기 때문에 무조건 장점이라고 생각할 수 없습니다.
ElastiCache for Redis는 스냅샷을 이용하여 복구를 지원하기 때문에 memcached 보다는 내구성이 좋지만, 전원이 나갈 경우 데이터가 휘발되는 정보로 영속성은 없습니다.
MemoryDB for Redis는 트랜젝션 로그를 활용하여 영속성을 지원하여 내구성이 좋습니다.

3. Amazon ElasticCache Common In-Memory Use Cases
3.1. caching
디스크 기반의 데이터베이스와 애플리케이션에서 데이터를 검색하는 것은 속도가 느립니다.
microseconds 의 지연시간과 높은 처리량을 위해서는 자주 사용하는 데이터를 In-Memory DB인 레디스에 저장하는것을 권장합니다.
주로 캐싱하는 종류로는 쿼리캐싱이나 전체 웹페이지 캐싱이 있습니다.
• 쿼리 캐싱(관계형, 비관계형, 객체, JSON, XML, 검색, 그래프, API)
• 전체 웹 페이지 캐싱(대부분의 앱 서버와 간단한 통합 모듈)
캐싱에서 소개되는 TTL과 evctions 에 대해 알아보자면
TTL은 지정한 시간이 지날 경우 바로 만료처리가 되는 것이 아니라 지정한 시간동안 데이터가 유지되는것을 보장하는 설정입니다.
TTL은 각 키를 생성 또는 수정할 때 명시적으로 할당하는 값으로, 글로벌 속성이 아닙니다.
또, 일부 키에는 TTL 설정이 필요하지 않을 수 있습니다.
또, 메모리가 꽉찼을 경우, 자동으로 제거하기 위한 Evictions 정책이 있습니다.
어떤 기준에 따라 키를 제거할 것인지 정책을 지정할 수 있습니다.
redis의 key는 해시함수를 이용하여 저장하기 때문에 키이름을 일부러 어렵게 설정할 필요 없습니다.
3.2. Leaderboards
리더보드는 변화하는 점수와 순위를 실시간으로 업데이트해야합니다.
따라서, 낮은 지연시간과 짧고 동시성이 높은 데이터 저장소인 레디스를 사용하는 것이 좋습니다.
게임 랭킹 시스템이나, 많이팔린 상품 등이 관련된 서비스라고 볼 수 있습니다.
sorted set 데이터 구조를 이에 활용하면 좋습니다.
아래와 같이 리더보드에 사용자의 활동점수를 합산하면 아주 간단하게 리더보드 구현이 가능합니다.

점수를 합산하거나 특정 구매기록을 쌓는 등의 기록을 쌇는 저장소로 no sql을 사용하여
히스토리가 쌓일 경우 이벤트로 score를 redis에 업데이트하도록 하면
별도의 연산없이 바로 읽어서 서비스를 할 수 있게 해줍니다.
이는, 화면의 UI와 서비스 특성에 따라 달라질 수 있는데
만약, 반드시 페이지 이동이 되어야하는 서비스라면, 위와 같은 구조로 서비스하는 것이 불가능합니다.
페이징 처리가 된다는 것은 결국 총 count를 알아야하기 때문에 이 경우에는 RDB를 쓰는 것이 더 합리적입니다.
(대표적으로 admin페이지)
리더보드나, 페이스북/인스타그램 피드, 구글 검색 결과 등과 같이 페이징 형태가 아닌 load more 형태로 다음 데이터를 불러오는 형태의 UI로 구성하는 데이터 부담이 줍니다.
Geospatial
- 배달업체. 특정 반경 안에 있는 가게를 알려줘
- 택시
- 주기적으로 택시들에 대한 실시간 위치를 트래킹 해야합니다.
- 500m 반경에 있는 택시 조회
- 내 위치에서 가까이에 있는 편의점
- dynamoDB에 기존 위치정보를 저장
실시간으로 변경되는 택시나 배달업체 위치 정보 등은 쓰기 트래픽이 빈번하고 많을 때에는, rdb 로는 구성이 어렵습니다. 이 경우에는 no sql를 활용해야 합니다.
Chat & Message 비권장
redis의 pub/sub
브로드캐스팅 방식
노드가 여러개일 경우, 여러개의 노드에게 메시지를 전달해야하는 부분때문에 성능이 떨어질 수 있습니다.
(노드가 많아질수록 성능이 떨어질수 있다)
shadded pub/sub 하나의 샤드에서만 pub/sub을
클러스터 n개의 샤드를
Message Queue
failover가 발생되었을 때 데이터 유실이 발생됩니다 -> 유실되면 안된다면 sqs를 사용하는것을 권장
Machine Learning
dynamodb에 매일 전 유저의 정적 추천목록을 갱신하여,
접속시 그 추천목록을 바로 서빙합니다.
사용하면서 클릭한 정보를 기반으로 추천정보를 위한 데이터를 수집합니다.(동적)
sorted set을 이용하여, 저장되어있는 추천목록을 서빙