2020. 7. 10. 12:06ㆍDB/Oracle
Oracle Database 구조
Oracle DB 서버는 Instance 와 Database로 구성되어있습니다.
- Instance
1-1) Buffer Cache
1-2) Shared Pool
1-3) Log Buffer - Database (file)
2-1) Datafiles
2-2) Redo Log File, Archive file
2-3) Control file
1. Instance
오라클의 Instance는 SGA(System Global Area)와 Background Processor로 구성되어있습니다.
SGA(System Global Area)는 데이터베이스 상에서 공유되는 영역으로 Buffer Cache, Shared Pool, Log Buffer 등으로 구성되어있습니다.
Background Processor에는 DBWR(Database Writer), LGWR(Log Writer), SMON(System Monitor), PMON(Process Monitor)이 있습니다.
1-1) Buffer Cache
데이터 파일로부터 읽어들인 데이터 정보가 보관되는 영역입니다.
LRU(Least-Recently-Used) 방식으로, 버퍼 캐시가 꽉찰 경우 가장 오랫동안 사용되지 않은 데이터를 지우고(age out) 새로운 데이터가 올라갑니다.
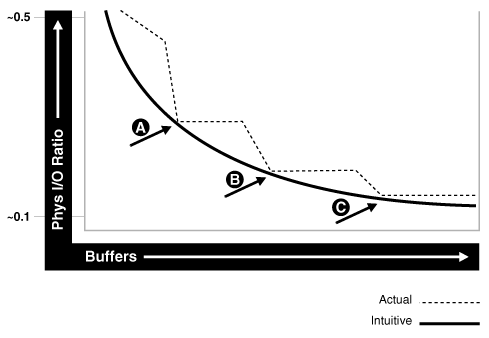
버퍼 캐시 크기가 커지면 데이터 파일을 거치지 않고 데이터를 읽어들일 수 있어 물리적 I/O 비율을 낮출 수 있고, 그에 의해 속도를 향상 시킬 수 있습니다.
하지만, 버퍼 캐시 크기가 적정 수준 이상 커지면(C) 물리적 I/O 비율의 변화는 없어지고, 그에 반해 CPU 오버헤드는 증가하여 Cache Hit Ratio가 감소하는 현상이 일어나기 때문에 버퍼크기는 적정 수준으로 설정하는 것이 좋습니다.
1-2) Shared Pool
Shared Pool은 고정영역과 동적영역으로 구분되는데, 고정영역은 SGA 관리 매커니즘 및 관련 파라미터 정보가 저장되는 곳으로 사용자가 지정할 수 없는 영역입니다.
SQL 실행 결과가 저장되는 영역은 동적 영역입니다.
동적 영역에는 Library Cache, Data Dictionary Cache로 구분됩니다.
Library Cache에는 실행한 SQL, SQL 분석정보 및 실행 계획이 저장되고, Data Dictionary Cache에는 테이블 메타정보가 저장됩니다(컬럼, 속성, 통계, 인덱스, 권한)
이전에 실행한 적 있는 SQL을 다시 실행할 경우, 이전에 만들었던 shared sql area를 재사용 합니다.
동일한 SQL 문장은 공유한다는 것은 다른 말로 메모리를 공유한다는 의미이며, 이는 구문 분석 시간이 감소시킵니다.
단, 빈칸, 대소문자, 주석 등을 포함한 텍스트의 완전하게 일치해야만 재사용 되므로 이 점을 주의해야 합니다.
사용자 프로세스가 쿼리를 실행하면 서버 프로세스에서 해당 쿼리를 처리합니다.
쿼리는 Parse → Execute → Fetch 단계를 거쳐서 결과를 반환하는데, Shared Pool은 그중 Parse 단계에서 사용됩니다.

Shared Pool의 Parse 단계 - Soft Parse
- Syntax(문법), privilege(권한) 체크
- Shared Pool에 해당 SQL 정보가 존재하는지 체크
- Execute
Shared Pool의 Parse 단계 - Hard Parse
- Syntax(문법), privilege(권한) 체크
- Shared Pool에 해당 SQL 정보가 존재하는지 체크
- Optimizer (실행계획 선정)
- Shared Pool에 SQL, 실행 계획 등을 저장
- Execute
먼저 쿼리 문법과 실행 권한을 체크한 후, Shared Pool을 조회합니다.
만일 Shared Pool에서 쿼리가 조회되면 Optimizer 하위 과정을 생략하고 저장된 정보를 이용하여 실행됩니다. (Soft Parse)
조회되는 정보가 없을 경우에는 Optimizer 과정을 거쳐 최적의 실행계획을 조회하고 조회된 정보들을 Shared Pool에 저장한 후 실행됩니다. (Hard Parse)
하드 파싱 비중이 높을 수록 쿼리 재사용량이 줄기 때문에 메모리 부족 및 Lock이 발생할 수 있습니다.
쿼리 문법을 체크할 때에는 query transforming도 내부적으로 실행됩니다.
query transforming은 잘못 작성된 코드를 변경하여 속도를 개선해줍니다.
WHERE id LIKE 1000;→WHERE id = 1000;
% 없이 LIKE 조회할 경우 equals 연산으로 변경됩니다.
1-3) Log Buffer
DB에 대한 변경사항이 발생했을 시, DBWR(Database Writer)가 작동하기 전에 LGWR(Log Writer)가 Redo Log Buffer Cache에 변경사항을 저장합니다.
Redo Log Buffer Cache에 저장된 변경사항은 일정 수준 채워지면 Redo Log File에 저장됩니다.
2. Database (file)
물리적 파일형태로 저장된 데이터입니다.
2-1) Datafiles
오라클 데이터베이스는 하나이상의 논리적 저장구조의 tablespace를 갖고 있으며, 이 tablespace는 datafile이라는 물리적인 파일 형태로 저장됩니다.
논리적 데이터베이스 구조의 데이터인 table, index 등의 정보들은 모두 datafiles 내에 파일 형태로 저장되어있습니다.

Block은 I/O 최소단위입니다.
기본 블록 사이즈는 DB_BLOCK_SIZE에 설정할 수 있고, 일반적으로 사용가능한 블록사이즈는 2K, 4K, 8K, 16K, 32K 입니다.
블록사이즈를 8K로 설정했을 때 Table Full Scan과 Index Scan 방식 각각의 전반적인 성능이 좋아, 최신 Oracle DB의 기본 블록사이즈는 8K로 설정되어있습니다.
extent는 인접한 데이터 공간에 같은 정보를 저장하기 위해 연속적인 block 공간을 미리 확보해둔 것입니다.
segment는 table, index와 같은 정보를 저장하기 위해 할당된 연속적인 공간으로, extent set으로 구성되어있습니다.
참고로 partition, lob, mview는 segment로 구성되어있지만, view는 segment로 저장되어있지 않습니다.
2-2) Redo Log File, Archive file
redo log는 오라클 DB에서 인스턴스 장애 발생했을 시 데이터베이스를 보호하기 위한 장치로, 오라클 DB의 복구 작업에서 가장 중요한 부분입니다.
Redo Log는 최소 2개 이상의 Redo Log File로 구성되어 있는데, 이는 archiving 중에 나머지 하나를 언제나 사용가능하도록 하기 위함입니다.
2-3) Control file
Oracle DB의 물리적 구조를 기록한 바이너리 파일입니다.
database 이름, datafiles 경로 및 이름, redo file 경로 및 이름 등의 정보를 가지고 있습니다.
oracle 이 사용하는 파일로, DBA가 변경할 수 없습니다.
Control file은 database를 열때 반드시 필요하며, 마운트시에 이 파일이 손상되었을 경우에는 복구가 어려울 수 있습니다.
++ 이미지 출처
[1] Using the V$DB_CACHE_ADVICE View
[2] Introduction to Data Blocks, Extents, and Segments